Datamanagement
1 Loading Dataset
# Laden des Datensatzes
library(readstata13)
library(tidyverse)## ── Attaching packages ───── tidyverse 1.2.1 ──## ✔ ggplot2 3.1.0.9000 ✔ purrr 0.2.5
## ✔ tibble 1.4.2 ✔ dplyr 0.7.7
## ✔ tidyr 0.8.2 ✔ stringr 1.3.1
## ✔ readr 1.1.1 ✔ forcats 0.3.0## ── Conflicts ──────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()library(magrittr)##
## Attaching package: 'magrittr'## The following object is masked from 'package:purrr':
##
## set_names## The following object is masked from 'package:tidyr':
##
## extract#Daten als Objekt importieren
econ <- read.dta13(file="data/offline/econometrics.dta" ,
convert.factors=F,
nonint.factors = F)
# Subsample with 5000 Observations
econ <- econ [sample(c(1:nrow(econ)),size = 5000,replace = FALSE),]2 Recoding/Variable declaration
!! Marcel here: not sure if we should stick with car::recode. I personally don’t like it and prefer classic R with [], but its so much more code-intensive…
library(car)## Loading required package: carData##
## Attaching package: 'car'## The following object is masked from 'package:dplyr':
##
## recode## The following object is masked from 'package:purrr':
##
## some# Variable Alter generieren
econ$alter = 2003 - econ$gebjahr
econ$alter [econ$alter == 2004] <- NA # entfernen der fehlerhaften
#sex
econ$sex <- factor(econ$sex,levels = c(1,2),labels = c("männlich","weiblich"))
# Ueberstunden recodieren 0=nein, 1=ja
econ$over = recode(econ$tp72,"2=0;-2=NA;-1=NA; 3=NA")
# Vertragliche und tatsaechliche Wochenarbeitszeit
# Missings bereinigen
econ$contract = recode(econ$tp7001,"-3=NA;-2=NA;-1=NA")
econ$actual = recode(econ$tp7003,"-3=NA;-2=NA;-1=NA")
econ$contract = econ$contract/10
econ$actual = econ$actual/10
# Vertrauen
# "Trust in people" und "Can't rely on anybody" recodieren
econ$trust = recode(econ$tp0301,"-1=NA")
econ$rely = recode(econ$tp0302,"-1=NA")
econ$netinc = recode(econ$tp7602,"-3=NA;-2=NA;-1=NA")
# Nur relevante Variablen werden übernommen
econ_data <- econ[,c("netinc","alter","sex","contract","actual","trust","rely")]
head(econ_data)## netinc alter sex contract actual trust rely
## 10086 1303 54 weiblich 37 38 2 3
## 13896 2000 55 weiblich 44 44 2 3
## 12161 NA 34 weiblich NA NA 3 1
## 8327 NA 22 weiblich NA NA 2 2
## 3865 NA 2 männlich NA NA NA NA
## 6975 NA 7 männlich NA NA NA NA# Delete NAs
econ_data <- na.omit(econ_data)
# Einkommen Kategorisiert in Quartile
hist(econ$netinc)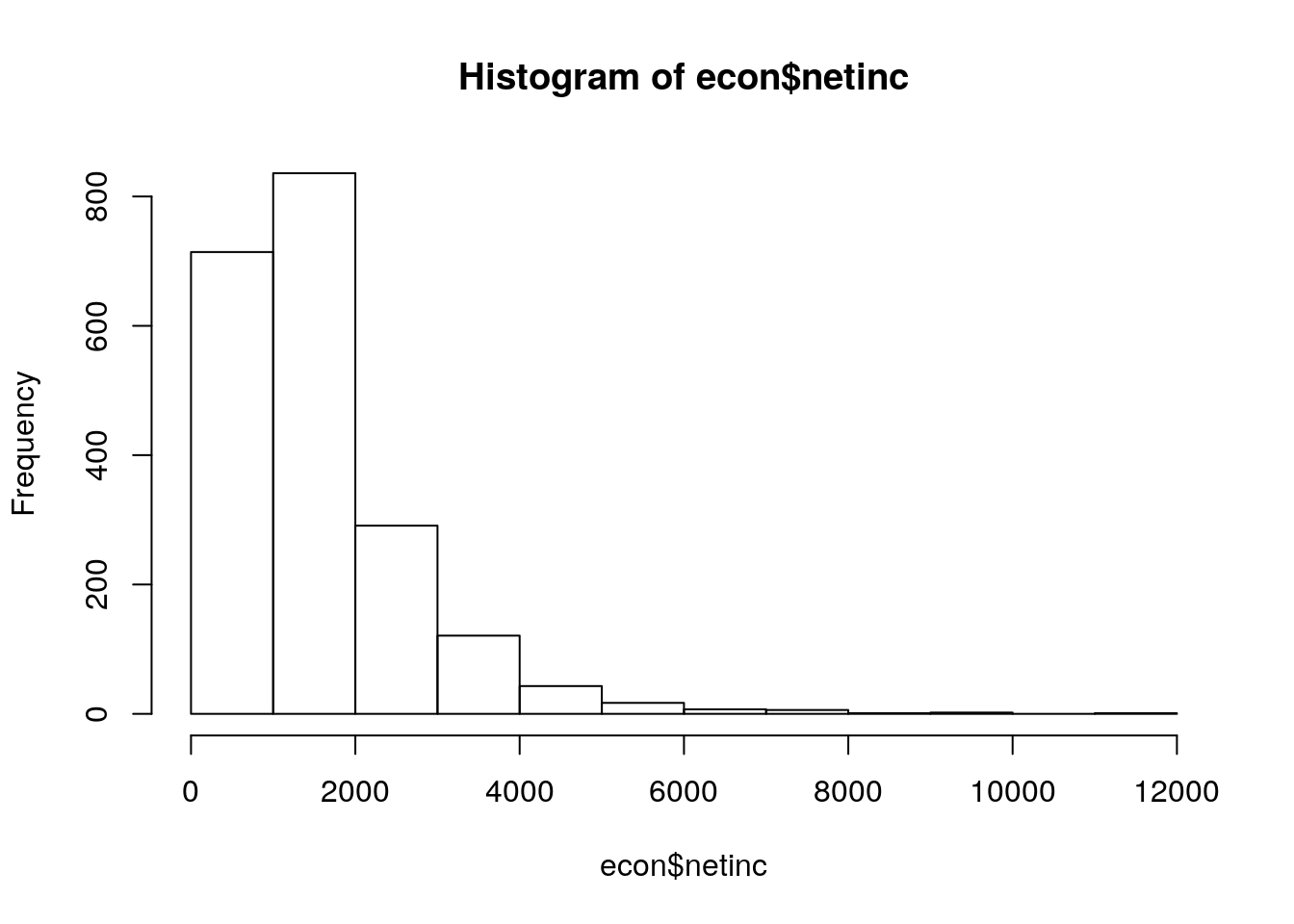
quantile(econ_data$netinc)## 0% 25% 50% 75% 100%
## 57 800 1381 1900 7700econ_data$inc_kat <- NA
econ_data$inc_kat [econ_data$netinc < quantile(econ_data$netinc)[2]] <- "Q1"
econ_data$inc_kat [econ_data$netinc >= quantile(econ_data$netinc)[2] & econ_data$netinc < quantile(econ_data$netinc)[3]] <- "Q2"
econ_data$inc_kat [econ_data$netinc >= quantile(econ_data$netinc)[3] & econ_data$netinc < quantile(econ_data$netinc)[4]] <- "Q3"
econ_data$inc_kat [econ_data$netinc >= quantile(econ_data$netinc)[4] ] <- "Q4"
table(econ_data$inc_kat)##
## Q1 Q2 Q3 Q4
## 401 432 394 4393 Advanced DM: The tidyverse
Some of the most important functions when it gets to datamanagement stem from the tidyverse-packages and most notably dplyr. We can only provide you with a small overview here, but if you understand mutate, summarise and group_by, you should be good to go.
3.1 Mutate
We can easily add variables (or transformed versions of others) to a knew dataset by adding a new variable through mutate.
For example, assume we wanted to add a squared age term:
econ_data <-
econ_data %>% mutate(alter_squared = alter^2)
head(econ_data)## netinc alter sex contract actual trust rely inc_kat alter_squared
## 1 1303 54 weiblich 37.0 38.0 2 3 Q2 2916
## 2 2000 55 weiblich 44.0 44.0 2 3 Q4 3025
## 3 100 45 weiblich 40.0 40.0 3 2 Q1 2025
## 4 560 46 weiblich 19.2 19.2 3 3 Q1 2116
## 5 950 44 weiblich 30.0 30.0 3 2 Q2 1936
## 6 1702 33 männlich 38.5 43.0 2 3 Q3 10893.2 Summarise
Summarise allows us to summarise certain variables, such as certain features of netincome.
econ_data %>%
summarise(mean = mean(alter,na.rm = T),
sd = sd(alter,na.rm = T))## mean sd
## 1 40.33914 11.486863.3 group_by
The same is also possibled for grouped structures. Say, for example, you would want to calculate seperate values for different genders:
econ_data %>%
group_by() %>%
summarise(mean = mean(alter,na.rm = T),
sd = sd(alter,na.rm = T))## # A tibble: 1 x 2
## mean sd
## <dbl> <dbl>
## 1 40.3 11.5